Spatial Analysis of Big Data with pgvector: Finding the Nearest Point among 100 Million Points in Istanbul

Introduction
In today’s data-driven world, the analysis of geographic data is becoming increasingly important, often involving large datasets. In this blog post, we will explore how to utilize powerful tools like PostGIS and pgvector to find the nearest points in a dataset of 100 million points.
What are PostGIS and pgvector?
PostGIS is an extension for the PostgreSQL database management system, adding support for geographic objects, allowing location queries to be run in SQL. pgvector, providing high-performance query capabilities on vector data types.
Data Preparation
The first step is to prepare the large dataset required for analysis. For example, this dataset could be obtained from a mapping application or sensor data. In this example, we will be working with a dataset consisting of 100 million points.
- Pull the PostGIS Docker Image: First, you need to pull the PostGIS Docker image from Docker Hub. You can do this by running the following command in your terminal or command prompt:
docker pull postgis/postgis2. Start the PostGIS Container: Now, you can start the PostGIS container. Use the following command to start the container:
docker run -d - name postgis -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres e -p 5432:5432 postgis/postgis3. Access Container: Inside the container, you can install the pgvector extension.
docker exec -it postgis bashsudo apt install postgresql-16-pgvector4. Connetct to PostgreSQL: Once connected to PostgreSQL, you can install the pgvector extension by running the following SQL command:
CREATE EXTENSION pgvector;5. Create table and create random 100 million points: Our first step involves creating random 100 million points within the districts of Istanbul.

CREATE TABLE point_vector (
id SERIAL PRIMARY KEY,
name varchar,
geom geometry,
vector vector(2)
);INSERT
INTO
point_vector (
name,
geom,
vector
)
SELECT
dump.name name,
geom,
ARRAY[st_x(geom),
st_y(geom)]::vector vector
FROM
(
SELECT
ist.ilce_adi name,
(
ST_DumpPoints(
ST_GeneratePoints(
geom,
3000000
)
)
).geom geom
FROM
ist
) AS dump;6. Indexing: HNSW and IVFFlat.
HNSW: An HNSW index creates a multilayer graph. It has better query performance than IVFFlat (in terms of speed-recall tradeoff), but has slower build times and uses more memory. Also, an index can be created without any data in the table since there isn’t a training step like IVFFlat.
IVFFlat: An IVFFlat index divides vectors into lists, and then searches a subset of those lists that are closest to the query vector. It has faster build times and uses less memory than HNSW, but has lower query performance (in terms of speed-recall tradeoff).
max_parallel_maintenance_workers: Speed up index creation on large tables by increasing the number of parallel workers.
ivfflat.probes: A higher value provides better recall at the cost of speed, and it can be set to the number of lists for exact nearest neighbor search (at which point the planner won’t use the index).
SET max_parallel_maintenance_workers = 7;
SET ivfflat.probes = 10;
CREATE INDEX ON point_vector USING ivfflat (vector vector_l2_ops) WITH (lists = 1000);Table:
SELECT count(*) FROM point_vector
--result: 117.000.000 million rowsSELECT * FROM point_vector limit 100;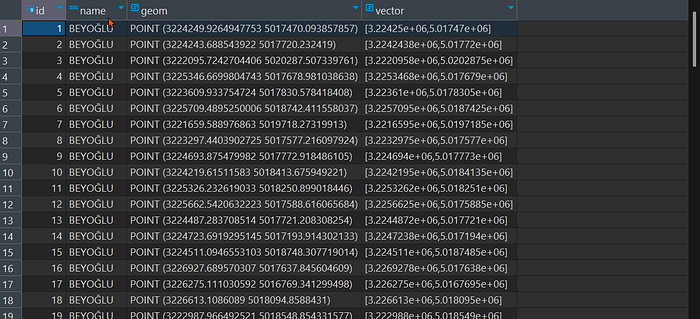

Finding Nearest Points
Once the data is prepared, we can use pgvector to find the nearest points to a given point. This process is optimized for large datasets, thanks to the vector database technology provided by pgvector.
Example 1: The 15 nearest points within a distance of 100 meters were found, with results obtained in milliseconds.
SELECT * FROM point_vector
WHERE vector <-> ARRAY[3225920.79,5017380.40]::vector < 100
ORDER BY vector <-> ARRAY[3225962.27,5017408.38]::vector LIMIT 15;
-- result: 329msExample 2: The nearest points within a distance of 100 meters were found.
SELECT name,geom,vector <-> ARRAY[3225962.27,5017408.38]::vector distance
FROM point_vector
WHERE vector <-> ARRAY[3225962.27,5017408.38]::vector < 100
ORDER BY distance ;
--result: 1.286s
-- 6000 rows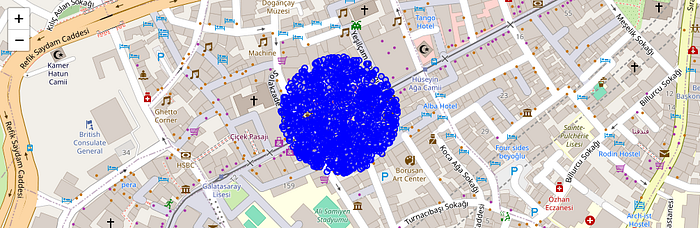
Example 3: The closest 100,000 points were found, with results obtained in milliseconds.
SELECT count(*) FROM (SELECT name,geom,vector <-> ARRAY[3225962.27,5017408.38]::vector distance
FROM point_vector
ORDER BY distance LIMIT 100000 ) ;
--result: 320msResults and Applications
We can visualize and interpret the results of the analysis. Additionally, we can discuss how the nearest points found can be utilized in specific application areas such as logistics, geographic exploration, or natural disaster management.
Conclusion
In this blog post, we’ve covered the process of finding the nearest points in a large dataset using PostGIS and pgvector. These powerful tools play a crucial role in geographic data analysis and provide valuable insights across various application domains.
Resources
Pgvector: https://github.com/pgvector/pgvector
PostGIS: https://postgis.net/
